
Considering using Large Language Models (LLMs) for your business but worried about data security and potential risks? You’re not alone, and you’ve come to the right place!
LLMs are like my 5-year-old niece. Her goal is to play Subway Surfers, and she’ll sign up for ads, download spam messages, and do anything to get back into the game, often compromising my phone in the process. LLMs operate similarly – they’re not fully aware of their surroundings and are focused on providing a response, sometimes even giving attackers what they want.
In this series of posts, we will explore the intriguing world of LLMs and data security, as identified by OWASP. We’ll discuss what your developers need to know and consider while setting up LLM applications.
- 🐞 Prompt Injection
Enterprise LLMs have access to privileged information but can be accessed by untrusted free-text inputs, making them vulnerable to attacks. These models blur the line between data and instruction, changing their behavior.
Prompt injection involves overriding the original instructions in the prompt and tricking the LLM into performing malicious activities. There are two types of prompt injections:
- Direct Prompt Injection or “Jailbreaking”
- Indirect Prompt Injection
Direct prompt injection is a technique where an attacker manipulates the input to a language model or AI system to produce specific, often malicious, outputs. A recent famous example is tricking a car dealership sales bot into agreeing to sell a 2024 Chevy Tahoe for $1

Figure 1 Prompt injection (R) to jailbreak LLM
Indirect prompt injection is when an attacker delivers the prompt via an external source. For example, the prompt could be included in training data or output from an API call.


Figure 2 – Diagram of a malicious prompt sent by Gaston to delete Adam’s profile
- 🐞 Insecure Output Handling
Insecure output handling occurs when outputs from LLMs lack proper validation, sanitization, and handling before being passed to other systems, leading to XSS or CSRF attacks or even AI worms!
Remember the Samy worm in 2005, the fastest-spreading virus? Samy wrote an invisible script that forced profile visitors to add him as a friend and copied itself to their profiles, spreading rapidly. This behavior can be replicated in LLMs using an “adversarial self-replicating prompt,” [research paper][Github]
It “tricks” the model into generating its own additional prompt, which it then responds to by carrying out the tasks.


Figure 3 – Diagram of how a malicious prompt can self-replicate.
- 🐞 Data Poisoning
Data poisoning involves intentionally altering the training set or fine-tuning phase to embed vulnerabilities, hidden triggers, or biases. This compromises the model’s security, efficiency, and ethical standards, leading to unreliable results. It can mislead users, potentially resulting in biased opinions, misleading followings, or even hate crimes.
- 🐞 Model Denial of Service
An attacker can exploit LLMs by consuming an unusually high amount of resources, affecting the quality of service and increasing costs. Attackers can also bombard the LLM with inputs that exceed the context window of the model.
- 🐞 Supply Chain Risks
Supply chains in large language models (LLMs) can be vulnerable, affecting the training data, models, and deployment platforms. For example, a developer might choose an old, unsupported model. A major concern is the terms and conditions for retraining models with user data. David Imel, on the WaveForm podcast, talks about how companies are scouring the world for more data to train on, now that they have already trained on publicly available data.
Recently, Adobe revised their terms and conditions, which led to concerns on social media about data theft. Adobe later clarified that the changes were meant for content moderation.



Figure 4 – Adobe’s Terms and Conditions
Pickle files are one way to serialize machine learning models. Attackers can create a model that, when loaded, executes code giving them access to the victim’s machine, potentially gaining full control. In this example, you can see how a calculator opens up when the model is loaded.
- 🐞 Sensitive Information Disclosure
LLM applications have the potential to reveal sensitive information, proprietary algorithms, or other confidential details through their output. This is common when retrieving information from databases using Retrieval-Augmented Generation (RAG).

7. 🐞 Insecure Plugin Design
LLM plugins are extensions that the model automatically uses during interactions. They are often used to add functionality or features to a larger software platform or system.
The model controls these plugins, and applications can’t control how they run. Poor design or implementation can pose significant security risks. They can be a gateway for data leaks and unauthorized access to sensitive data.
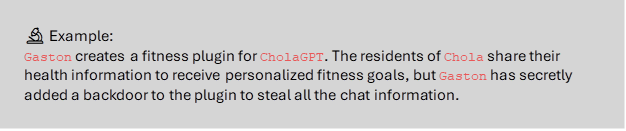
8. 🐞 Excessive Agency
LLMs interacting with external systems tend to perform tasks beyond the intended scope. These unintended actions can include sending u,, nauthorized emails or deleting information from databases.

- 🐞 Overreliance
LLM applications are often built with the assumption that they are accurate and provide correct results due to the vast amount of knowledge they have consumed. However, this is not always the case. LLMs can and will often generate misleading, incorrect responses if the correct context is not given. A recent viral example is how Gemini AI recommended that we eat one rock per day.

Figure 5 – Gemini AI recommending rocks for food
- 🐞 Model Theft
Model theft occurs when valuable proprietary LLM models are compromised, physically stolen, copied, or have their weights and parameters extracted to create a functional equivalent.
How can the last be possible, you ask?
Model weights capture different features of data and make up the model. For example, weights for ear shape, size, fur texture can be different for cats and dogs. A published paper explains how you can decode sequence of tokens from these model weights to jailbreak the model. Read the paper here.
If you are thinking, “Ugh, this seems too dangerous. I will just host my LLM privately and not let the data out of my network. No attacker can reach it,” think again. Securing your LLM applications depends on how the application is built and what the LLM has access to.
In the next post, we will explore different ways to mitigate these issues, routinely check for security vulnerabilities, and apply guardrails to protect your proprietary data.
To learn more about how we can help you navigate the complexities of LLM security and leverage AI effectively, visit our Artificial Intelligence page. Let’s work together to secure your business while unlocking the full potential of AI.
References
OWASP Top 10 – https://genai.owasp.org/
Wired article for AI Worms – https://www.wired.com/story/here-come-the-ai-worms/
Waveform Podcast – “Move Fast and Break Terms of Service” https://youtu.be/cfFYKkBgYkE?si=v84KirfaaDyXQI9O


